Single Engine + All Data :云器科技推出基于「增量计算」的一体化湖仓平台
数据平台领域发展 20 年,慢慢的变成为每个企业的基础设施。作为一个进入「普惠期」的领域,当下的架构已经完美了吗,主体问题和挑战是什么?在 2023 年 AI 跃变式爆发的大背景下,数据平台又该如何演进,以适应未来的数据使用场景?
数据平台领域发展 20 年,慢慢的变成为每个企业的基础设施。作为一个进入「普惠期」的领域,当下的架构已经完美了吗,主体问题和挑战是什么?在 2023 年 AI 跃变式爆发的大背景下,数据平台又该如何演进,以适应未来的数据使用场景?
本文将从以上问题的出发,盘点和整理技术演进的趋势,并提出一体化架构将是下一代技术趋势的方向。新架构通过创新的「增量计算」范式来统一数据分析中流、批、交互不同的计算形式,通过「湖仓一体」统一存储形态,真正的完成一体化 Kappa 架构。同时,新架构以湖仓存储为基础,具备开放性和扩展性,能够对接支撑 AI,具备进一步迭代和扩展能力。
第一阶段-孕育期:2003 年~ 2010 年,谷歌为支持搜索业务奠基大数据领域,以论文的形式公开架构和技术细节;Yahoo 开源其搜索后端的数据处理技术,并命名为 Hadoop。
第二阶段-发展期:2010 年~2020 年,两个关键事项有力地推动了大数据的发展:1)以 Hadoop 为核心的开源技术,即开源分布式大数据平台的繁荣发展;2)是云计算技术,极大程度上降低了大数据平台的建设门槛。当下主流的大数据平台大都在 2012 年前后开始发展,比如 AWS Redshift 是云上数仓的典型代表;包括 Snowflake 的成立,阿里云与飞天大数据平台起步等;
第三阶段-普惠期:从 2020 年至未来的 10 年,我们大家都认为是大数据的普惠期。为什么这样讲,普惠期有两个特点,其一是业务进入收获期:我们能看到千帆竞发后,大部分企业被淘汰,少数企业通过竞争最终占领市场,并逐步形成规模,例如 Snowflake 2020 年上市;其二从技术角度来看,部分成熟场景下技术开始迭代式发展,如「批计算」、「流计算」和部分「交互分析」技术成熟后不断被后来者挑战;同时,场景继续外延不断引入的技术,如 AI 相关的技术由此外延衍生出来,呈现出对其他领域的辐射作用。目前我们能看到这几个特征同时具备。
当前典型的数据平台架构是计算部分采用 Lamdba 架构,存储层由数据湖或者数据仓库构建。AI 等基础设施尚在发展成熟中。

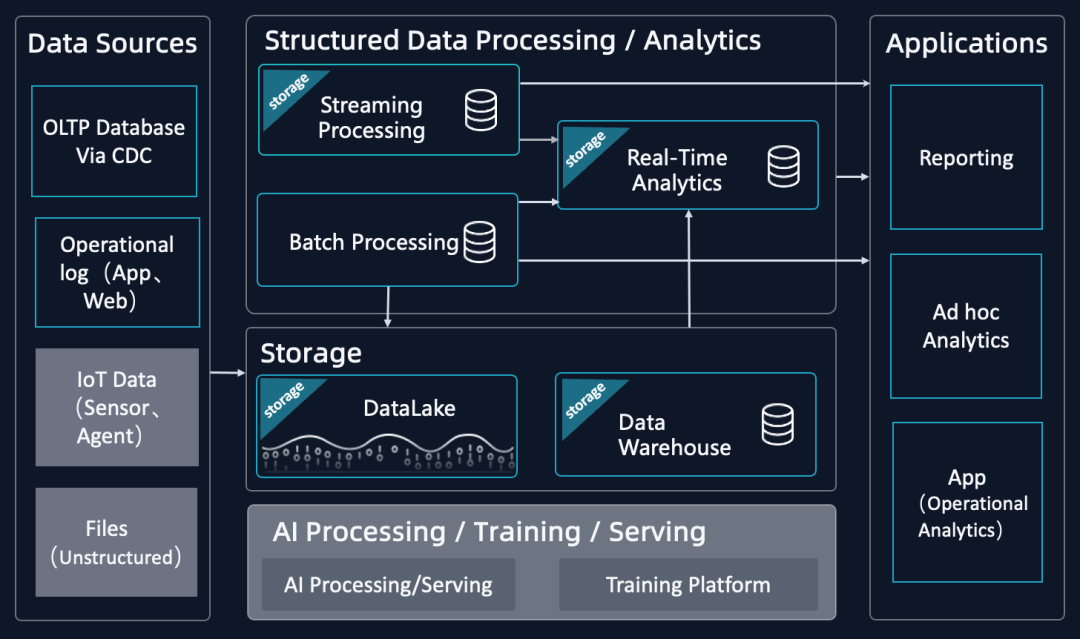
我们将当前数据平台简化为如下典型架构图,其中「不变」的部分用黑底来表示,「变」的部分用灰底来表示,如图下可见。
IoT、智能设备数据:在物联网普及之前,大多数据都是用人的行为数据。随 IoT 类技术发展,设备的数据会逐步成为另外一个主要的数据来源。
半结构化和非结构化数据:随着 AI 能力的增强,这部分数据开始被加速地采集上来。
数据分析引擎分为「批处理」、「流计算」、「实时分析」,也都有各自比较固定的数据处理和分析的场景,通过组合的方式满足多种业务需求,这个架构通常称之为 Lambda 架构。
数据存储架构分为「数据仓库」与「数据湖」,二者都不算新概念,使用场景也比较固定,大多数企业选择其一。例如 hadoop 体系就是一种典型的数据湖架构。
AI 相关的场景和架构还在发展中,场景差异大,尚未标准化。而最近火热发展的 LLM 又带来额外的变化:部分企业会选择,由一个特征工程开始到 Training 到 Serving 的端到端的 Pipeline;另一部分企业不再做特别多的 AI 训练,而是在 Huggingface 上下载一些已有模型,只做基础的 AI 处理。
综合上述,总结市面上大部分数据平台通常会选用组装式的 Lambda 架构,而其需要多个 API 接口与多种数据组件,数据冗余度高,开发维护复杂度高。面向未来,我们大家都认为结构化数据处理分析的趋势会是,由一个一体化的引擎,统一「流」、「批」和「交互分析」,进而提供统一接口、统一处理逻辑,提供多种优化指标的高覆盖度和灵活调整的能力。
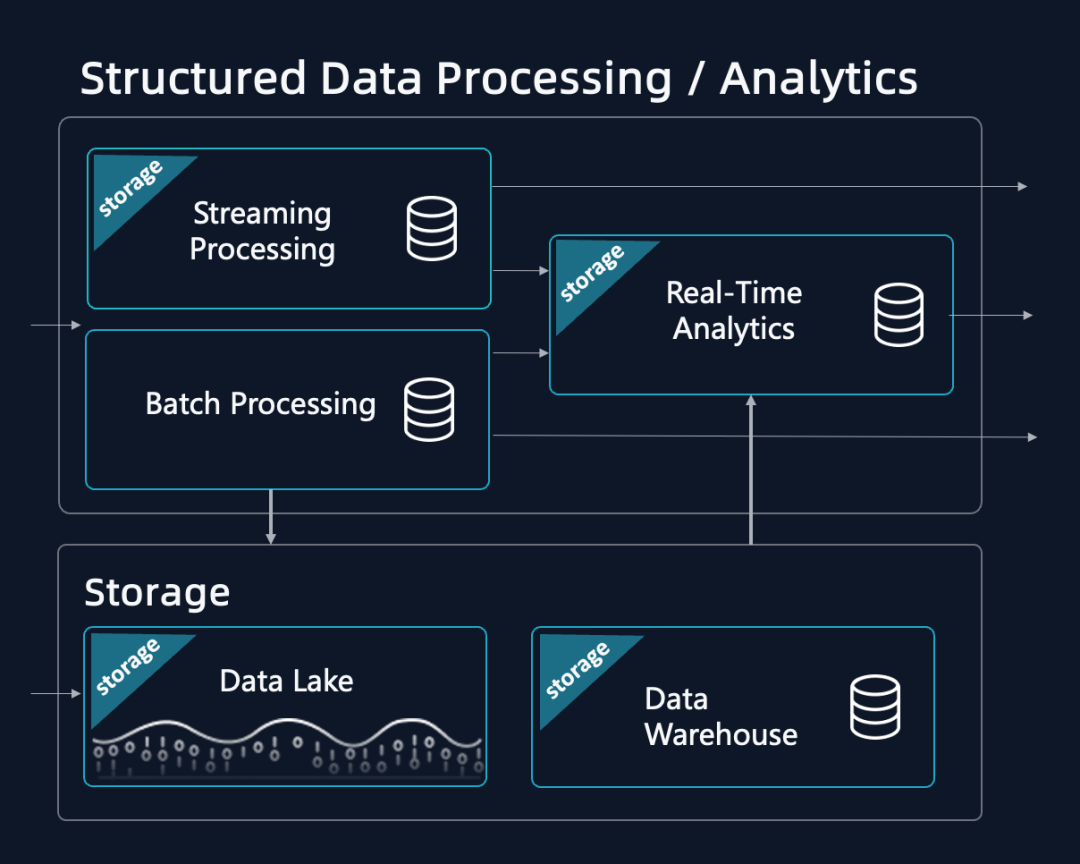
1.引擎数据语义均不统一,带来极高的开发和维护人力成本。三种引擎各自独立,查询语言、数据语义均不统一,数据在三种引擎间流转,开发和维护成本高。有统计数据表明用于运维这些系统的人力成本与资源成本相当。
2.异构存储,多套元数据,带来大量的计算和存储冗余和管理成本。三种引擎各自独立但又相互关联,为做到局部语义统一,带来大量的显性、隐形的计算冗余。同时三种引擎通常配置各自独立的存储,带来大量的数据冗余和数据同步的成本。湖和仓采用外表关联,缺乏统一管理。统计这些计算和存储冗余带来数倍的成本负担。
3.缺乏满足业务变化的灵活性。三种引擎开发运维独立,且系统设计的优化方向不同。当用户业务需要调整三个引擎间的配置(重新调整数据新鲜度、性能和成本的平衡点),就需要复杂的修改和重复开发。通常统计当前数据架构一旦固定下来调整的周期在 3 个月以上,难以适应灵活多变的业务发展。
但要解决这样一些问题,统一成一体化架构,并非数据架构师们不想,而是确有几处难点,后文有详细论述。
发展中的/变化的」AI 新计算范式,传统数仓架构不能够满足,需要新架构的支持
AI 给数据平台带来新的挑战:AI 需要更丰富的数据,数据需要更多样的 BI+AI 应用。Data 与 AI 的关系不再是 Data+AI,而是 Data*AI数据平台不再是一对一的计算和存储架构,而是 m 对 n 关系的架构,这样的架构改变变化下,我们该思考的问题是,由单点优化思路建设起来的 lambda 架构,能否迎接 AI 的挑战,若无法,改变的方向是什么?
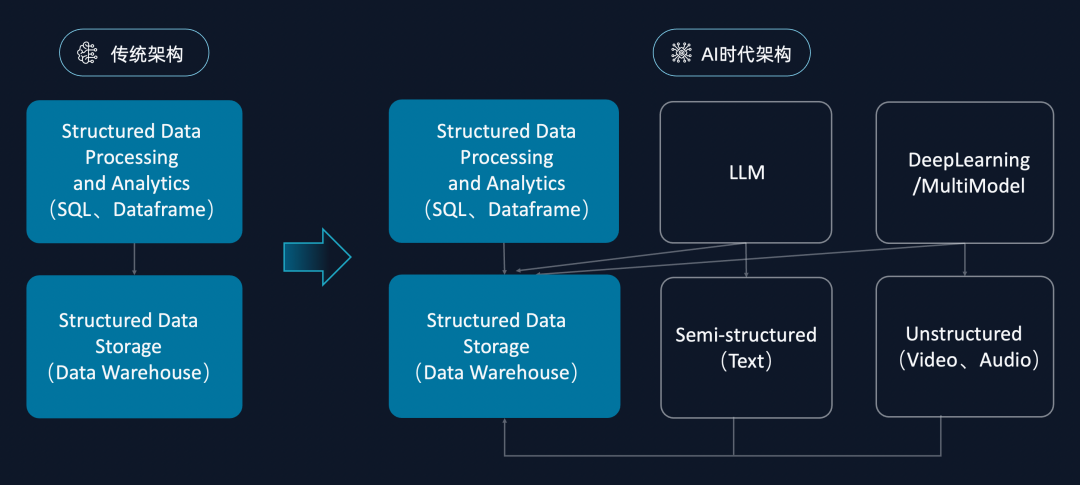
图 6: 从 1 对 1 的数仓架构,到 M 对 N 的多元异构开放架构
关系型数据库自 1970 年诞生,到 2010 年的 40 年时间里,都是采用传统的数仓架构(如上图左侧)面对结构化的数据处理和分析,所以存储系统的优化都是基于结构化数据的存储来进行的,最终迭代出来的标准化 SQL 引擎,也还是为了做结构化数据的分析。
而最近十年,特别是随着深度学习技术的发展,ML/AI 拓宽了数据平台需处理的数据类型,底层引擎模式随之改变:
改变一,引擎以往只能处理结构化数据二维表,现在能够最终靠 AI 处理包括 test 、json 在内的半结构化数据,和处理非结构化数据(音视图数据);
改变二,引擎模式的顶层计算架构也在改变,类似生成式 AI 对文本和数据的直接理解和解读,类似 code interpreter 通过理解数据语意做大模型的插件式、多语言融合式查询分析,是除 SQL 的二维关系表达和分析引擎外,将 AI 的计算能力纳入到引擎。
未来已来,面对 AI 带来的改变,我们大家都认为数据平台的架构更应有兼具一体化与开放性的设计。开放式湖仓一体架构,是面向 Data+AI 融合场景的新趋势。
如上所述,我们大家都认为能够面向未来的下一代数据平台,是一体化的、开放、支持 Data+AI 的湖仓平台,架构设计上:
面向 AI 部分,在湖仓一体底盘之上向上迭代,同时与下层存储及数据分析引擎,做融合计算。比如我们大家可以有 SQL 和 Python 的融合计算,通过这一种方式实现一个面向未来的存储架构。
组装式 Lambda 架构存在的问题是业界普遍有深刻体感的,也有很多技术/产品试图解决 Lamdba 架构的问题,但都不是很成功,为什么实现「一体化」的架构那么难?这主要有两个原因:批、流、交互计算的计算形态不同,优化方向也不同。
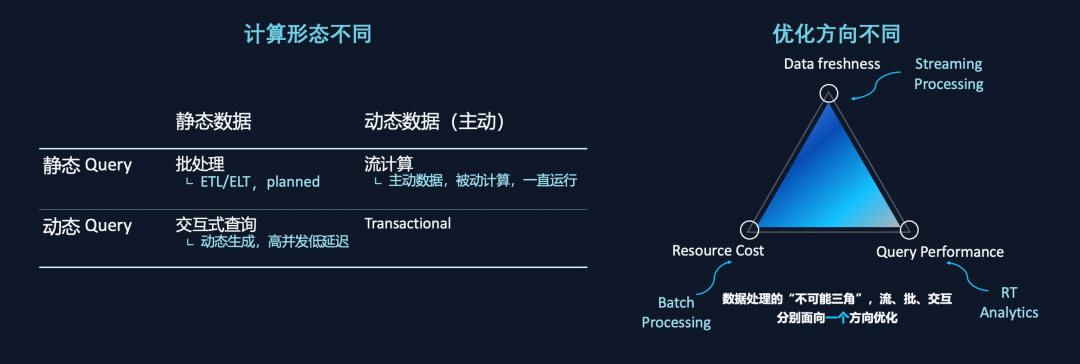
将数据状态分静态数据与动态数据两类。所谓静态数据就是当 Query 下发的一瞬间,计算是在数据的一个版本(称为 snapshot)上进行;而动态数据是指在持续变化中的数据,由数据主动驱动计算。数据 Query 也可分成静态 Query 和动态 Query 两类。所谓静态 Query 的意思是像天报表或者小时报表一样,我们大家都知道它在某一个时间点上会发生。动态 Query 是指,用户动态下发的,很难被预测。
由以上两个维度,可以划分出四个象限区间,能够准确的看出批处理、流计算、交互式分析分属不同象限:批处理是典型的静态数据加静态 Query 的流程,通常是一个 Pipeline 过程;交互分析是静态数据加动态 Query,高并发低延迟;批处理和交互分析,通常是计算向数据去,是主动计算处理被动数据的过程。流计算是动态数据加静态计算的过程,当 Plan 发起之后,就一直等待数据进入,是一个主动数据驱动被动计算的过程。
上图三角为数据平台不可能三角,即一个平台不可能同时实现数据新鲜度、低成本和高性能三个目标。如流计算优化的是数据的新鲜度,引擎等数据,为了使得下一条数据进来时计算的足够快,引擎是一直拉起的状态,Reserve 了大量资源。实时数仓系统是面向性能的,也需要等待数据,需要一个非常快的数据。批处理计算面向的是 Throughput,即 Latency 延迟,可提供很高的 Throughput,带来很低的 Cost。不同的优化方向使得三个引擎也不同。
Lambda 架构流行的核心原因是,流、批和交互计算,刚好覆盖了此三角,三个不同的引擎,每一个引擎的优化方向刚好是在一个角上。通过组合的方式满足多种业务的需求。下图更细节地比较批处理、流计算、交互式的异同。

批处理的存储是通用存储,采用数仓分层建模的方式,数据的中间表格能被共享,可以被其他查询优化。
而流计算是单独的内置存储,不可被共享,仅面向该计算模式优化;其中流计算两个作业之间的存储也不同,通常用 Kafka 做,是纯粹增量化的存储,且仅支持某一段时间的查询,不能做全量数据 Query。
批处理通常选择 Bulk Synchronous Parallel(BSP)调度模型,是一种逐层调度模式。批处理通常作业下发后,动态向 Yarn/Kubernetes 申请资源,具有极佳的资源使用效率,能够减少相关成本。缺点是会造成资源排队。
而交互分析为越来越好的性能,一般会用 Massive Parallel Processing(MPP)调度模型,资源需要保持预置,数据被静态划分好,面向低延迟和高性能优化,但有很高的成本。
综上能够准确的看出由于流、批、交互三种计算引擎的计算模型、数据驱动方式、存储系统模块设计、调度系统模块设计、资源模型等均不相同,都很难覆盖另外两个的场景,他们三者本身难以完成统一计算模式。
鉴于流、批、交互三种计算模式都不能完成模式的统一,我们提出第四种计算模式:增量计算。
增量计算定义:指的是将所有计算抽象成增量的形态,实现数据的一次计算、累次使用,节省计算资源,同时能提供灵活调整的「增量时间间隔」,达成批处理或者流处理效果。因增量方式明显降低资源使用,也能大幅度的提高交互分析的性能并降低延迟。
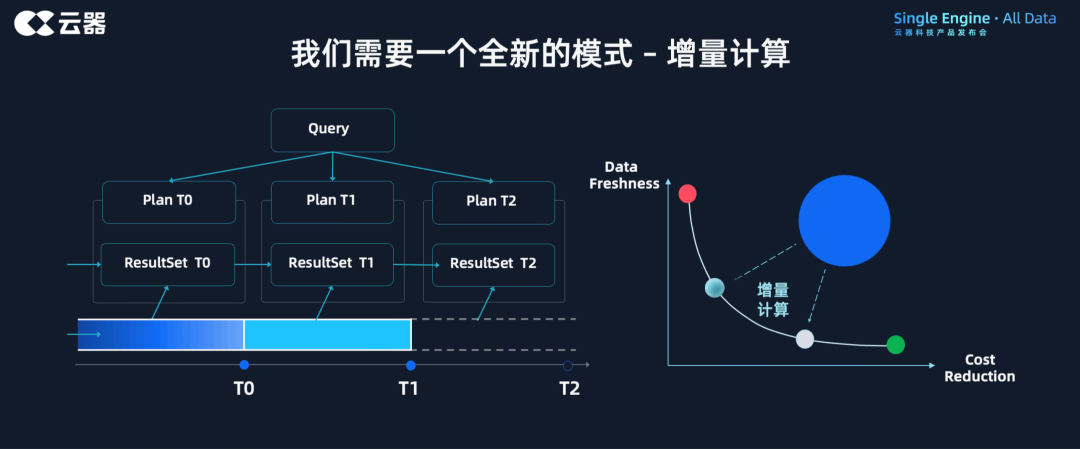
如左图所示,x 轴时间轴代表 T0、T1 和 T2,当 Query 下发时,T0 动态生成 Plan,基于当前最优数据和计算情况,在 T0 数据里得到结果集 ResultSet T0;当在 T1 时间下发同一个 Query 时,该 Query 的计算不再从 0 开始,而是在 T0 结果集的基础上,结合 T0 到 T1 这一阶段的数据,融合起来做增量计算,得到 ResultSet T1,同时在为 T2 计算做状态准备。
针对批处理,可以将其作为当 T0 为 0,从 T0 到 T1 的增量计算模式的特例,是一种从头开始的增量计算。在最佳实践里,用户通常不再保持按天的批处理,而是降低调度间隔来达成更好的近实时性。
针对流计算,流计算是天然的增量计算模型,能够最终靠缩短 T0 与 T1 中间间隔的时间来达成。
针对交互分析,与批处理类似,交互分析也可以抽象为增量化形态,并且更简单,因为没有后续,所以不需要再为下一阶段计算做准备。同时,因为部分交互分析的数据是持续写入的,部分之前的计算结果也可以被后来的作业利用,大幅度降低计算量。
调度增量计算的时间间隔,是由用户根据需要调整设定的。当把调度时间间隔调整的很短,例如调整为分钟或者秒级,整个计算模式就愈接近流计算,而如果把间隔调整天,计算模式就等同于批处理。也就是说,计算模式的改变,只需要调整调度就能实现!
第一,统一计算模式,进而能够统一引擎,从根本上解决 Lambda 的痛点。
第二,每次 Query 在下发的时候,能够准确的通过 T0、T1 中间的时间间隔做动态 Plan,找到其中最优 Plan 的调节流程。可以在一定程度上完成数据平台不可能三角的平衡点,基于数据新鲜度、性能、成本的动态平衡,灵活地在三者之间找到多种多样的平衡。
第三,结果集 ResultSet 均公开可用,能够支持所有其他引擎或者平台使用,更符合数仓建模设计逻辑,也更具开放性。
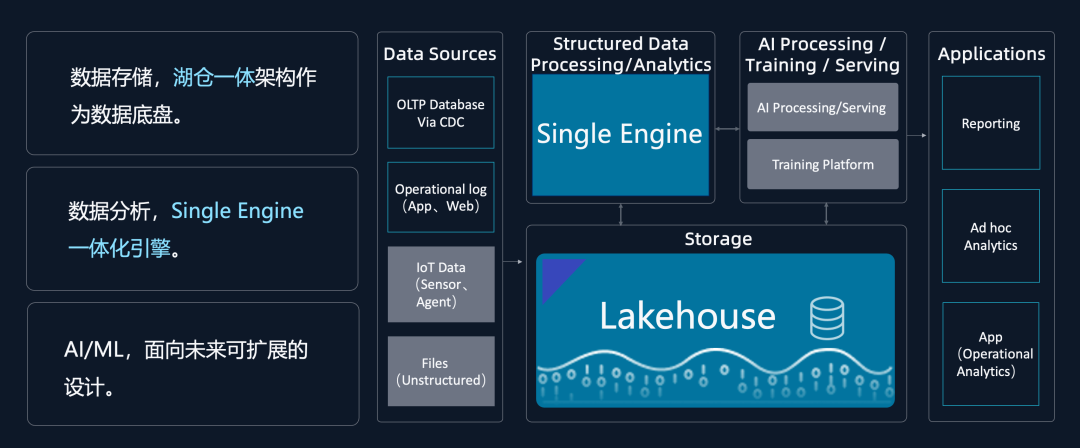
增量计算能解决计算模式的统一,即流、批、交互为一体;但对于数据平台整体架构而言,还需要统一存储和面向 AI 的能力,因此云器科技以增量计算为基础,提出 Single-Engine 的数据平台设计理念。

基于增量计算数据计算新范式,云器科技实现了 Single-Engine 一体化平台,包含如下三部分:
2.用通用增量存储的统一存储形态。在湖仓存储架构的基础上增加了通用增量存储,使得在湖仓之上能够做增量的表达,该存储需要做到以下三点:
实现大通用的存储,是能适应面向写入 Throughput 和查询高性能的两个维度进行优化。
实现数据的开放性,最终把数据的表达变成标准化的开源 Iceberg 存储格式,使得其它的引擎或者平台可以很方便地对接起来。
3.Share Everything 架构。在 ShareData 架构基础上增加了新维度,把数据、计算和资源三方拆开,使得批处理和交互分析在资源上可以做灵活调度。
至此,通过统一的计算模式、统一的增量存储,并将数据、计算和资源 Share Everything 化,最终构成了云器 Lakehouse 的 Single-Engine 一体化架构。
1.统一的接口,统一的语法/语义,统一且开放的数据表达(使得可以被其他引擎/工具消费)。数据与计算隔离,一套存储支撑多种运算模式。
2.提供面向数据新鲜度、查询性能和资源成本三方面的多种平衡点(而不是面向三个顶点的极致优化)。具备多点优化能力,同时能支持三者之间的灵活调整。
3.支持在平衡点之间做简单灵活的调节。调整应该是简单的,不需要修改大量代码,不要重新构建 Pipeline。
4.多种指标达到/超过当前主流产品的水平。通过 Single-Engine 在流、批、交互这三个场景上都有不逊于现在主流系统和架构的性能,甚至超越它们。
云器 Lakehouse 作为一体化数据平台,横跨实时、离线、交互分析等多个场景,为了客观地衡量数据集在不同场景下的表现,我们用业界标准的测试集在对应场景上,进行性能评估。特别的,云器 Lakehouse 由于采用了存算分离 share-everything 的系统架构,会通过限制 virtual cluster(虚拟计算集群 abbr. VC)计算资源的规格来保证测试数据与别的产品的规格一致。尽管这样的限制不利于发挥计算资源弹性伸缩的优势,云器 Lakehouse 仍然在多个场景下同时表现出优异的性能,如图 11 所示:
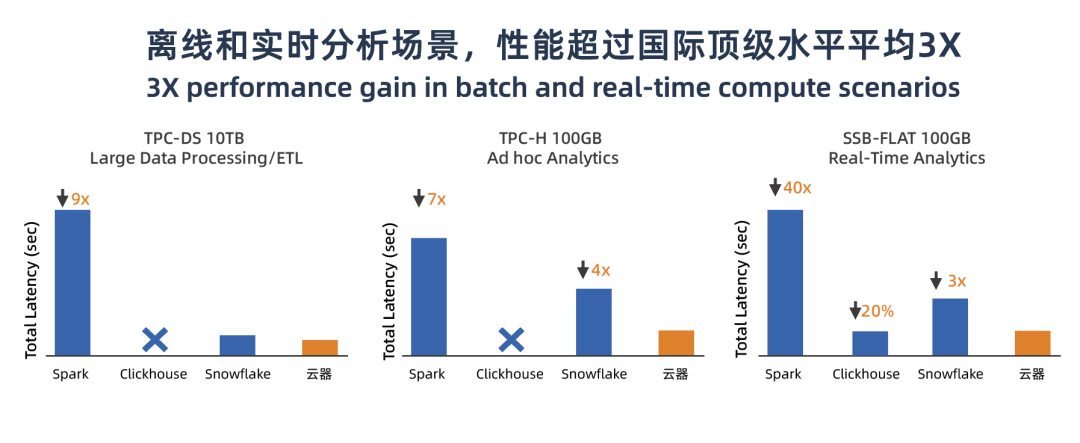
图 11-左 1:大数据分析场景,TPC-DS 10TB 是 TPC 发布的针对大数据系统的标准测试数据集,适合用于评估大数据处理及 ETL 处理过程,测试集包含对大数据集的统计、报表生成、联机查询、数据挖掘等复杂应用。以相同规格配置的处理时间评估,云器 Lakehouse 处理速度比 Snowflake 快 30%,是 Spark 处理的 9 倍;
图 11-左 2: 即时分析场景,TPC-H 100GB 是由面向业务的临时查询和并发数据修改组成,适合用于对 Ad-hoc 临时查询评估。云器 Lakehouse 不仅在处理速度上达到了 Spark 的 7 倍,且比 Snowflake 还要快 4 倍。
Process 场景:是单表下,单行的数据处理 json 展开的场景;
单流 join 场景:是双表下,左表是一个固定的维表,Join 右表是流动的实时表数据,这是一个标准的维表扩展场景;
单表聚合场景:是单表做 aggregation,流动数据的聚合分析场景;
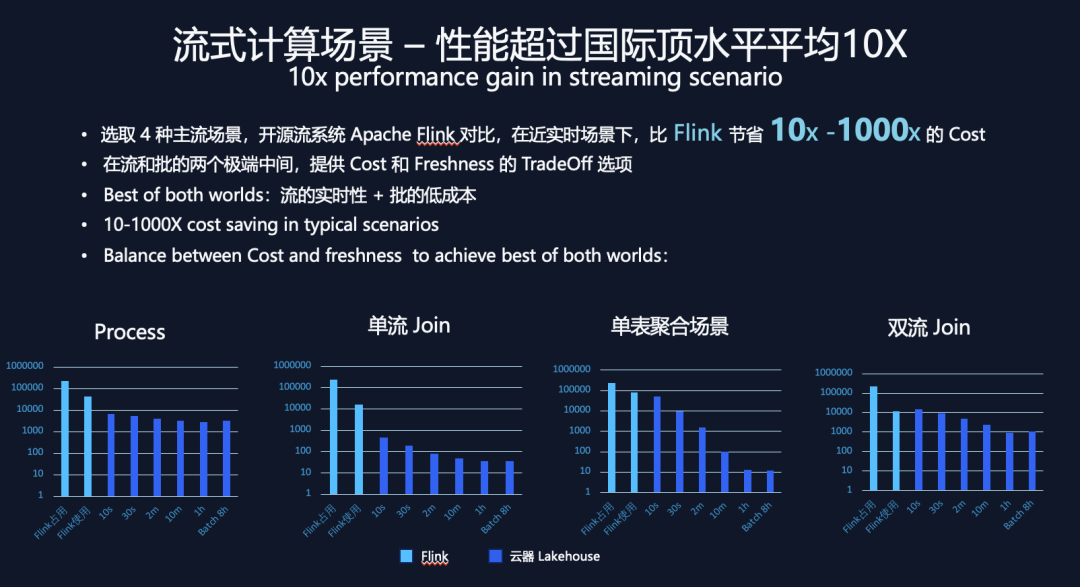
在每个场景以 Apache Flink 做参照对比分析,由于 Flink 是一个「主动数据被动计算」的过程,会有占用资源和实际使用资源的区别。如图 12 所示,每张图的前两个数据柱状图指标是 flink,第一个柱子代表 flink 的资源占用,第二个代表 flink 的实际资源使用。而云器使用增量计算的模式,没有资源占用和使用差异。6 个深蓝色柱子代表云器 Lakehouse 在不同的时间间隔的资源使用情况。
在 Process 场景和单流 join 场景(图 12-左 1 左 2)属于「无状态计算」,云器基于自研的向量化引擎实现,比 Flink 以行式处理引擎的方式快至少 10 倍以上,此外能够正常的看到无论调度间隔是 10 秒或间隔 8 小时,云器流计算资源消耗差异不大。
单表聚合场景和双流 join 场景,由于要考虑历史数据/状态,属于「带历史状态计算」,调度间隔时间的调整会很大程度上影响计算资源的消耗,从图 12 右 1 右 2 两张图可见,云器 Lakehouse 在 10 秒调度间隔下做到和 Flink 持平,在 30 秒或调至 1 小时的准实时调度间隔,性能的节省能够达到百倍甚至千倍。
上述测试表明,云器 Lakehouse 在流处理场景上,比 Flink 有 10x-1000x 的资源消耗节省。并且,基于增量计算在「流」和「批」两个极端场景中间,让数据新鲜度和处理成本可以被精益平衡;让用户既能够得到「流」的实时性,又能够获得「批」的低成本。
针对当前主流数据架构的痛点和挑战,云器科技提出通过增量计算的方式,统一流、批、交互三种计算模式,实现了 Single-Engine 的架构,覆盖数据不可能三角,给用户更好的提供灵活的多种性能成本平衡点,并超越当前主流引擎的性能。此外,云器 Lakehouse 在湖仓架构上做到开放并实现 All data 技术理念,一体化的湖仓平台能够同时支持 BI 和 AI 的 Workload。基于一体化架构,云器提出 AI4D 的新方向,通过 AI 的方式更好地优化平台效率。(注:AI4D 领域另有专题技术白皮书论述)


公司地址:北京市朝阳区酒仙桥路4号751 D·Park正东集团院内 C8座105室 极客公园